Week 9
Social Statistics and
Machine Learning
SOCI 316
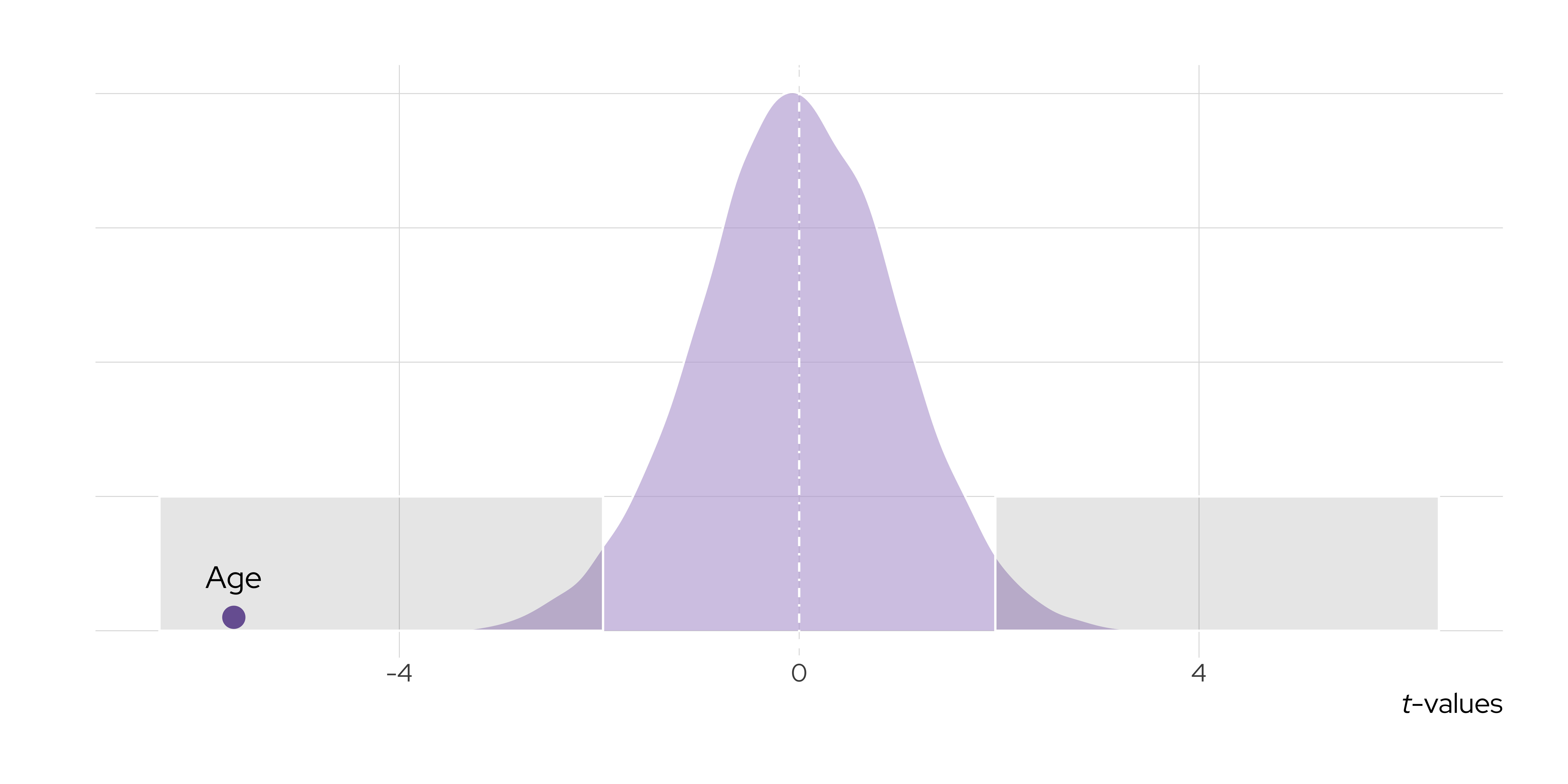
Let’s Use Our Model
Range of Predictions—Truncated Sample
Show the underlying code
library(marginaleffects)
avg_predictions(survival_truncated, variables = "age") |>
as_tibble() |>
ggplot(mapping = aes(x = age, y = estimate)) +
geom_line(colour = "#b7a5d3", linewidth = 1.1) +
geom_ribbon(mapping = aes(ymin = conf.low,
ymax = conf.high),
fill = "lightgrey",
alpha = 0.3) +
theme_bw()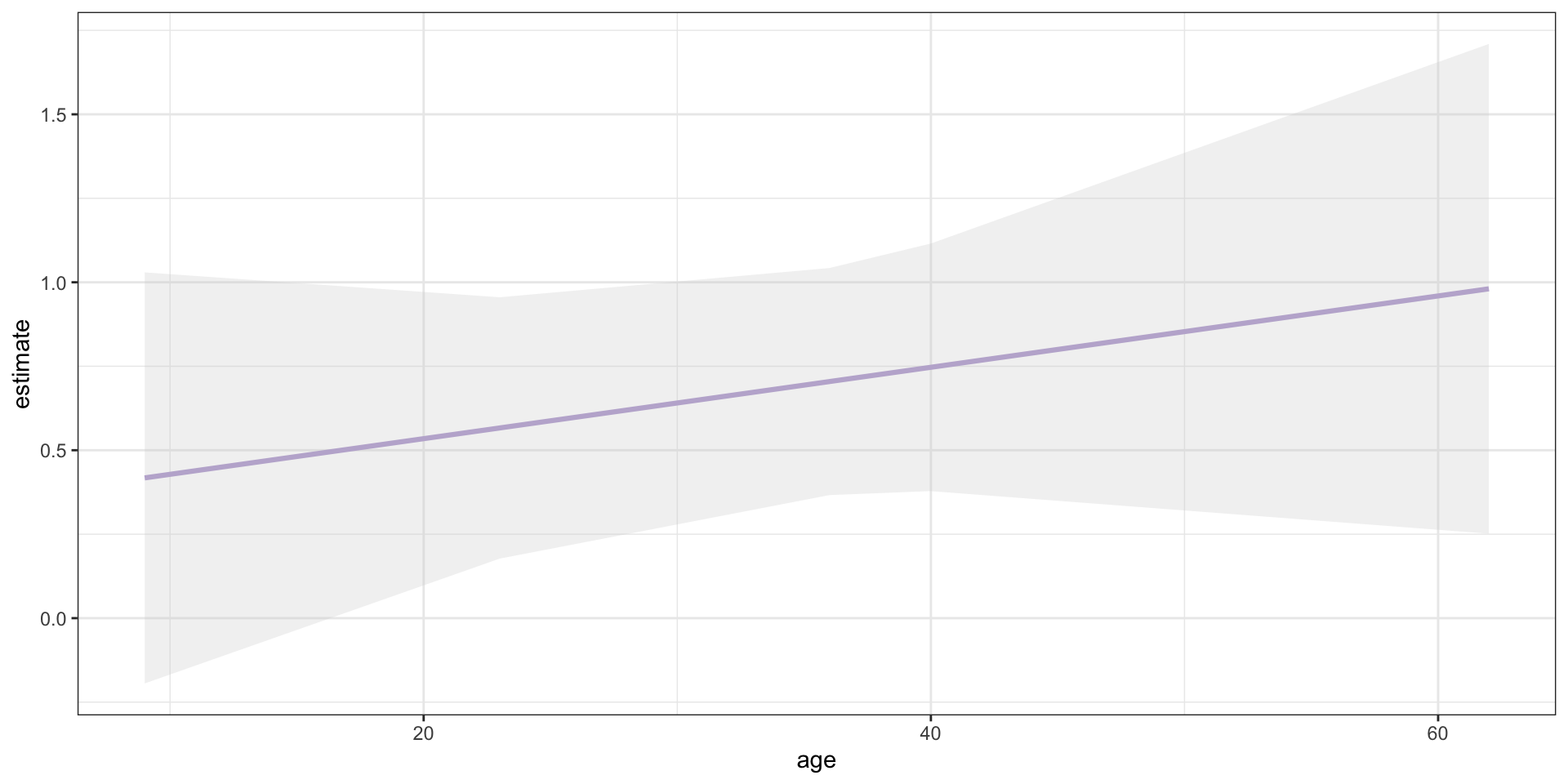
Let’s Use Our Model
Range of Predictions—Full Sample
Show the underlying code
survival_full <- lm(survived ~ age, data = titanic)
avg_predictions(survival_full, variables = "age") |>
as_tibble() |>
ggplot(mapping = aes(x = age, y = estimate)) +
geom_line(colour = "#b7a5d3", linewidth = 1.1) +
geom_ribbon(mapping = aes(ymin = conf.low,
ymax = conf.high),
fill = "lightgrey",
alpha = 0.3) +
theme_bw()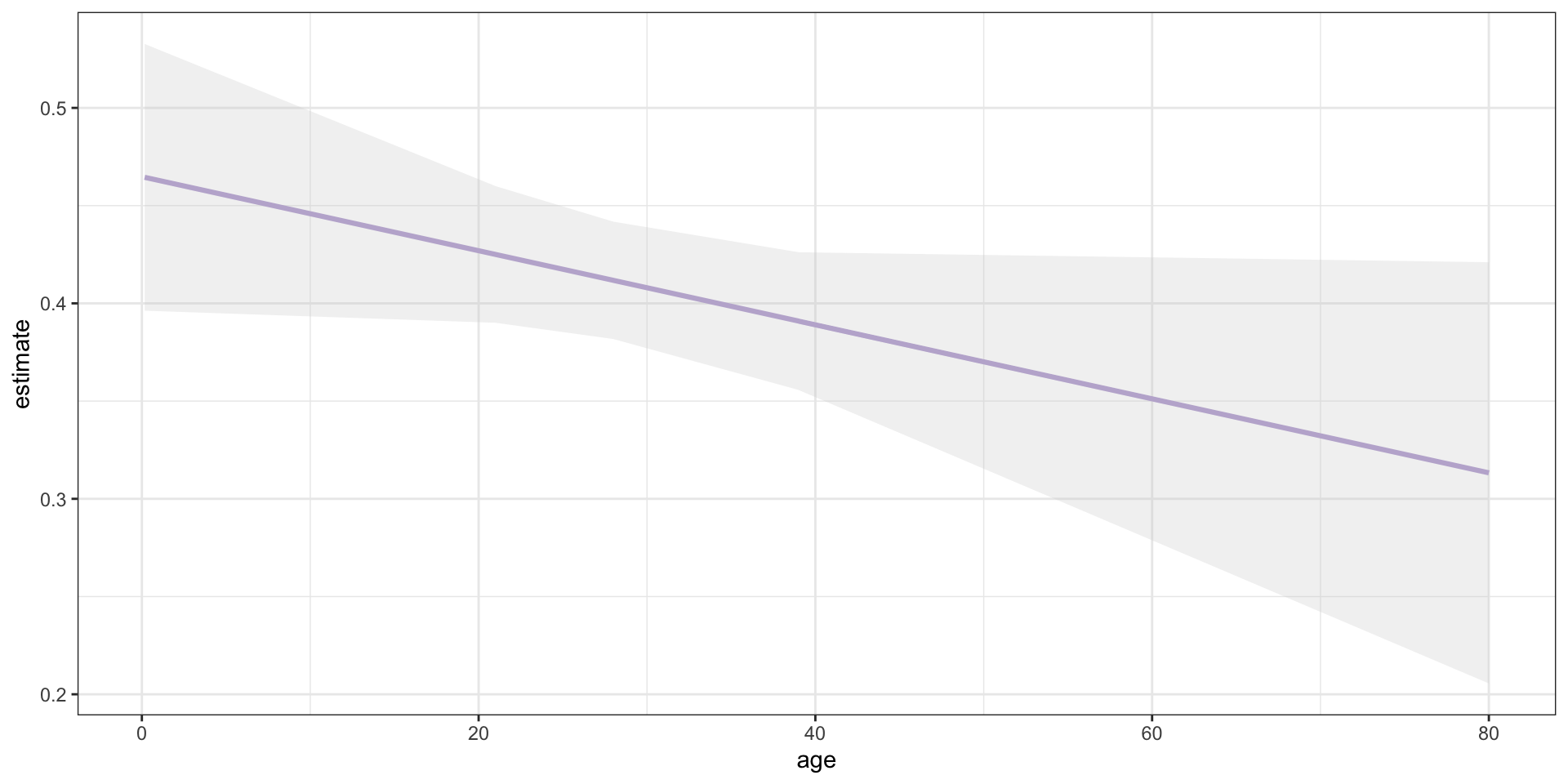
Supervised Machine Learning (SML) cont.
An Illustration
# A tibble: 80,000 × 6
fruit shape weight_g colour texture origin
<chr> <chr> <dbl> <chr> <chr> <chr>
1 apple spherical 150 red crispy china
2 banana curved 120 yellow creamy ecuador
3 orange spherical 148 orange juicy egypt
4 watermelon spherical 4500 green juicy spain
5 strawberry conical 13 red juicy mexico
6 grape spherical 5 green juicy chile
7 mango ellipsoidal 240 yellow juicy india
8 pineapple conical 2100 yellow juicy costa rica
9 apple spherical 140 green crispy usa
10 banana curved 110 yellow creamy ecuador
# ℹ 79,990 more rows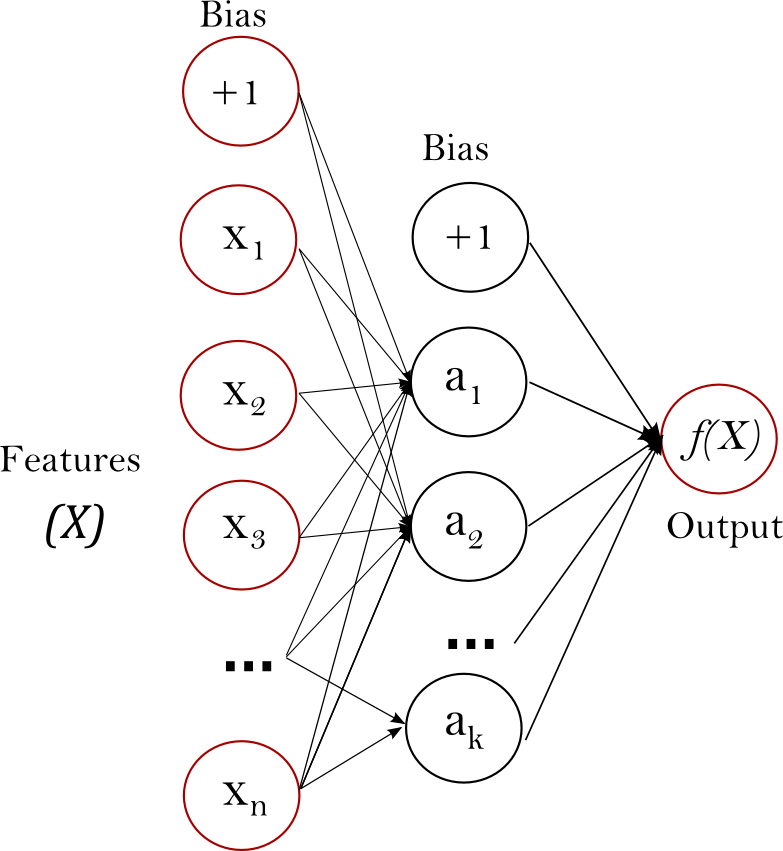
# A tibble: 1 × 6
fruit shape weight_g colour texture origin
<chr> <chr> <int> <chr> <chr> <chr>
1 <NA> conical 6 red juicy china # A tibble: 8 × 2
fruit probability
<chr> <dbl>
1 apple 0.03
2 banana 0
3 orange 0.05
4 watermelon 0
5 strawberry 0.71
6 grape 0.21
7 mango 0
8 pineapple 0 # A tibble: 1 × 1
prediction
<chr>
1 strawberry
Unsupervised Machine Learning (UML) cont.
An Illustration
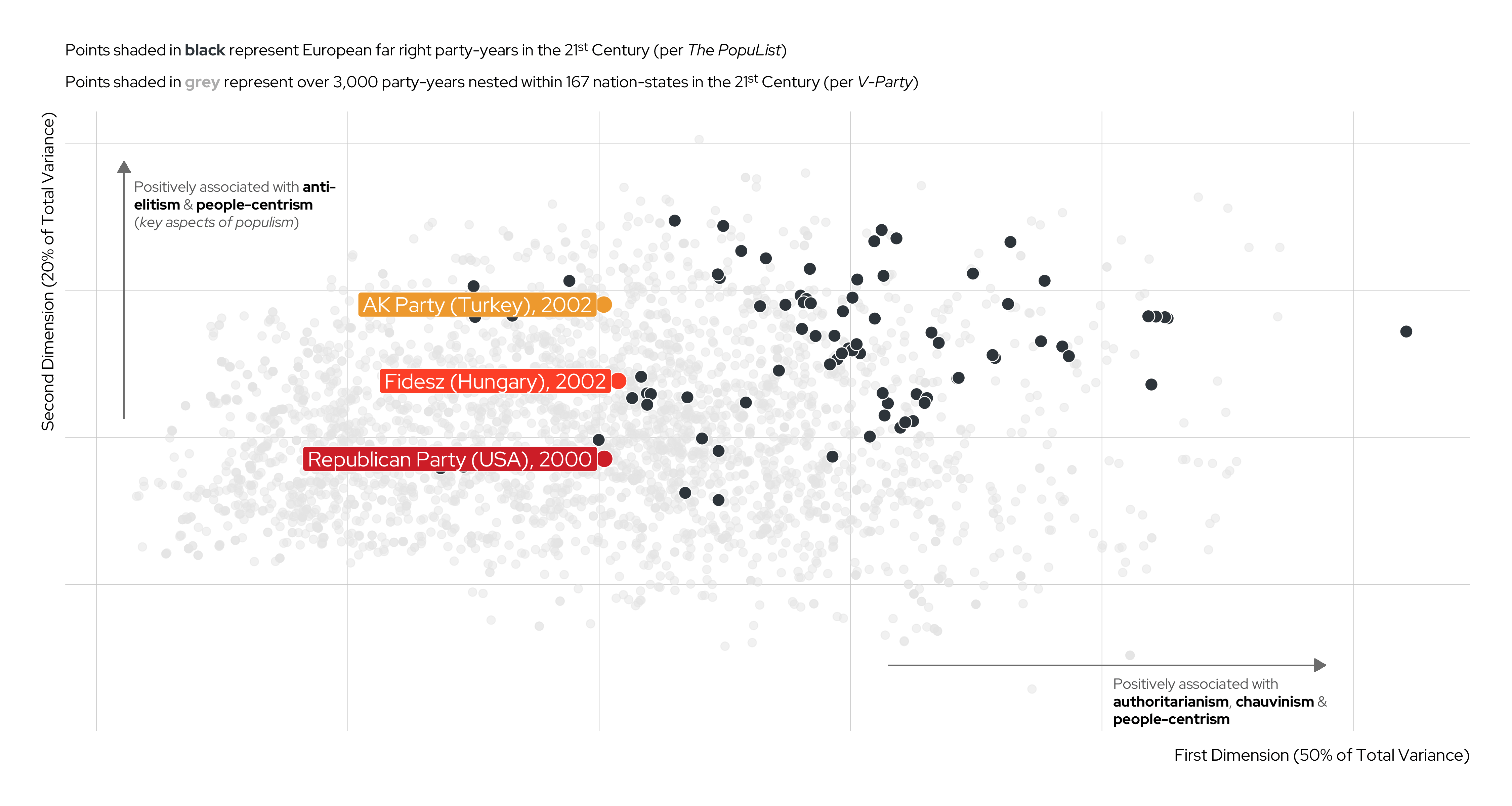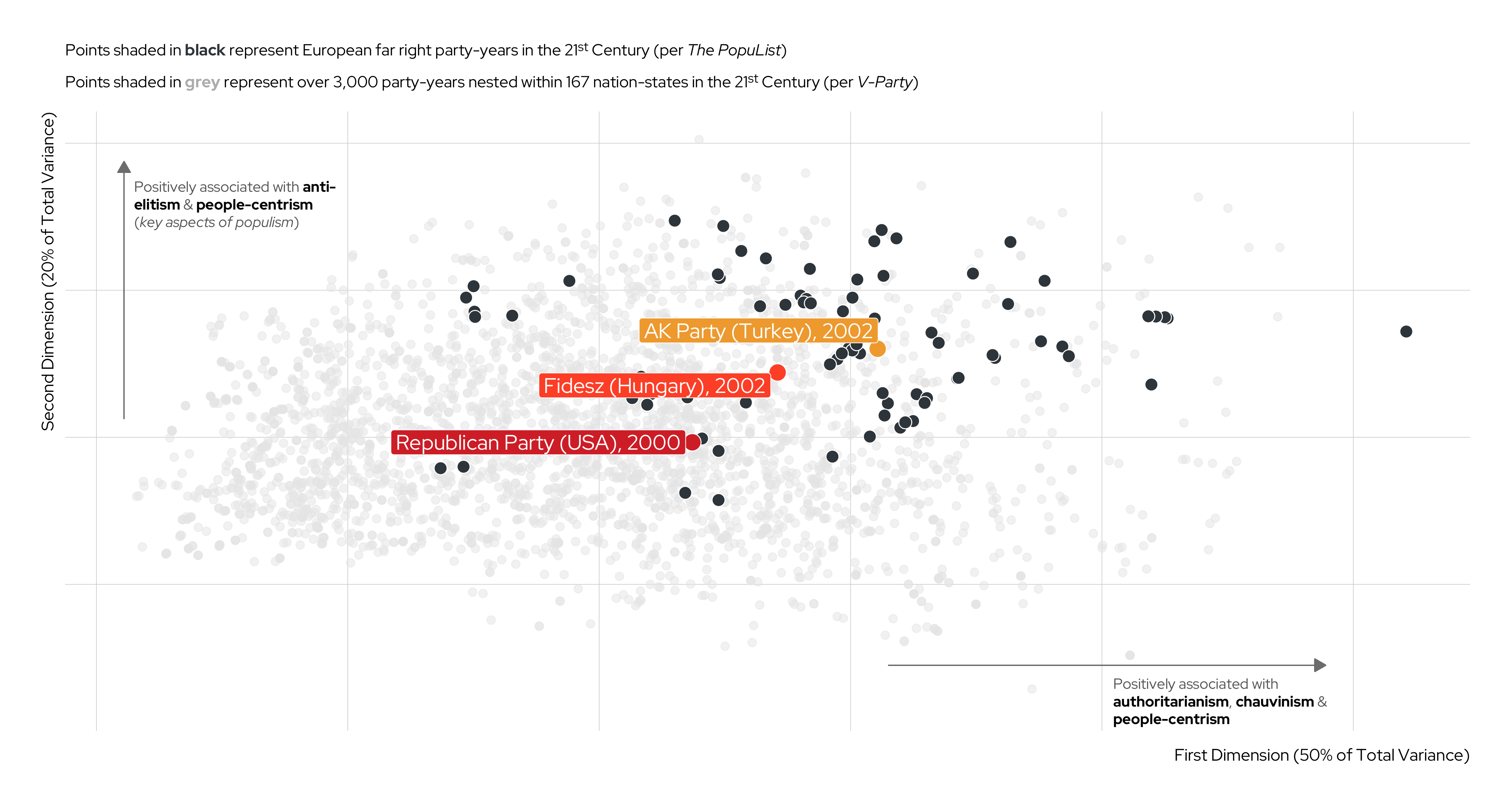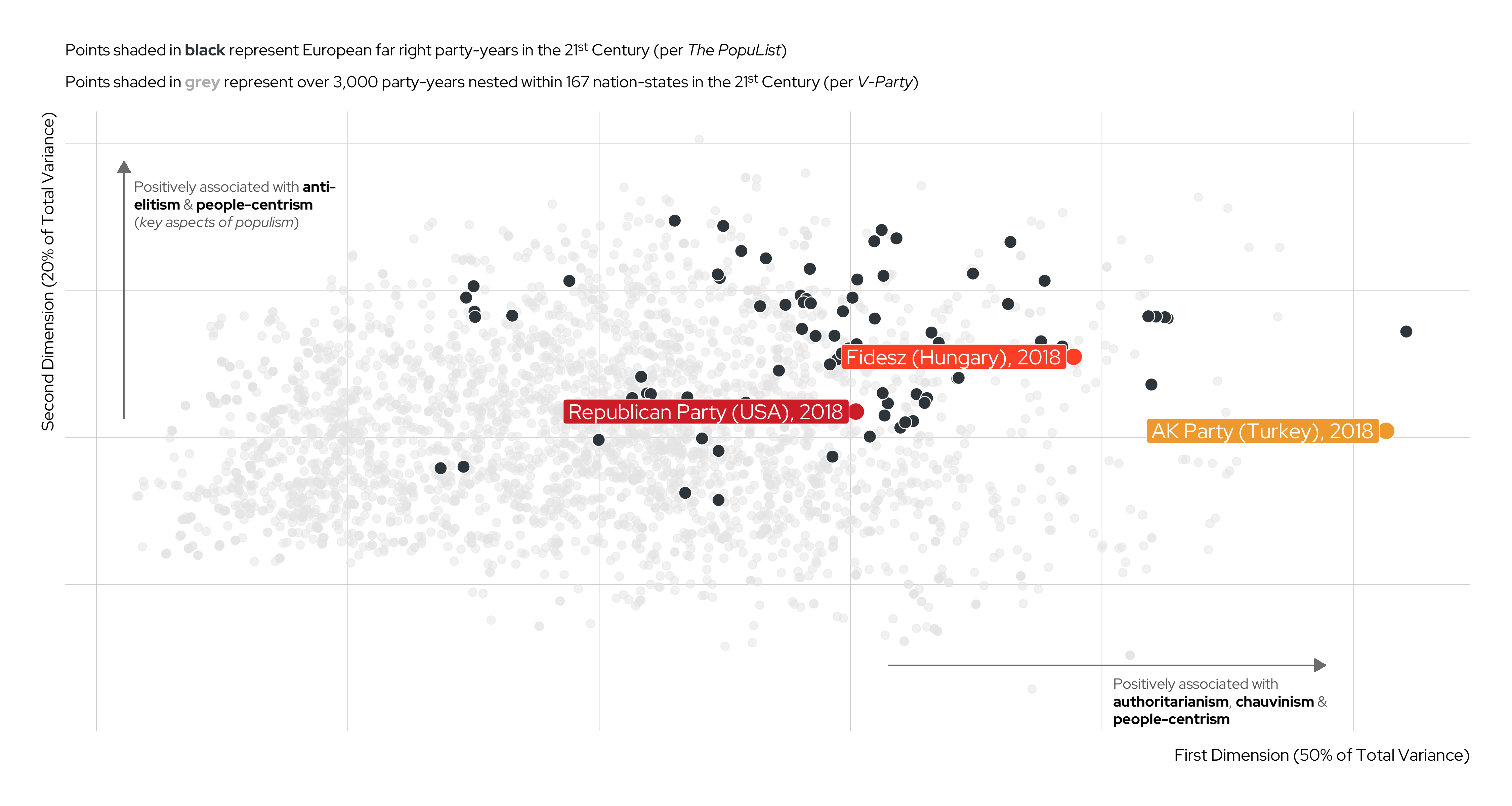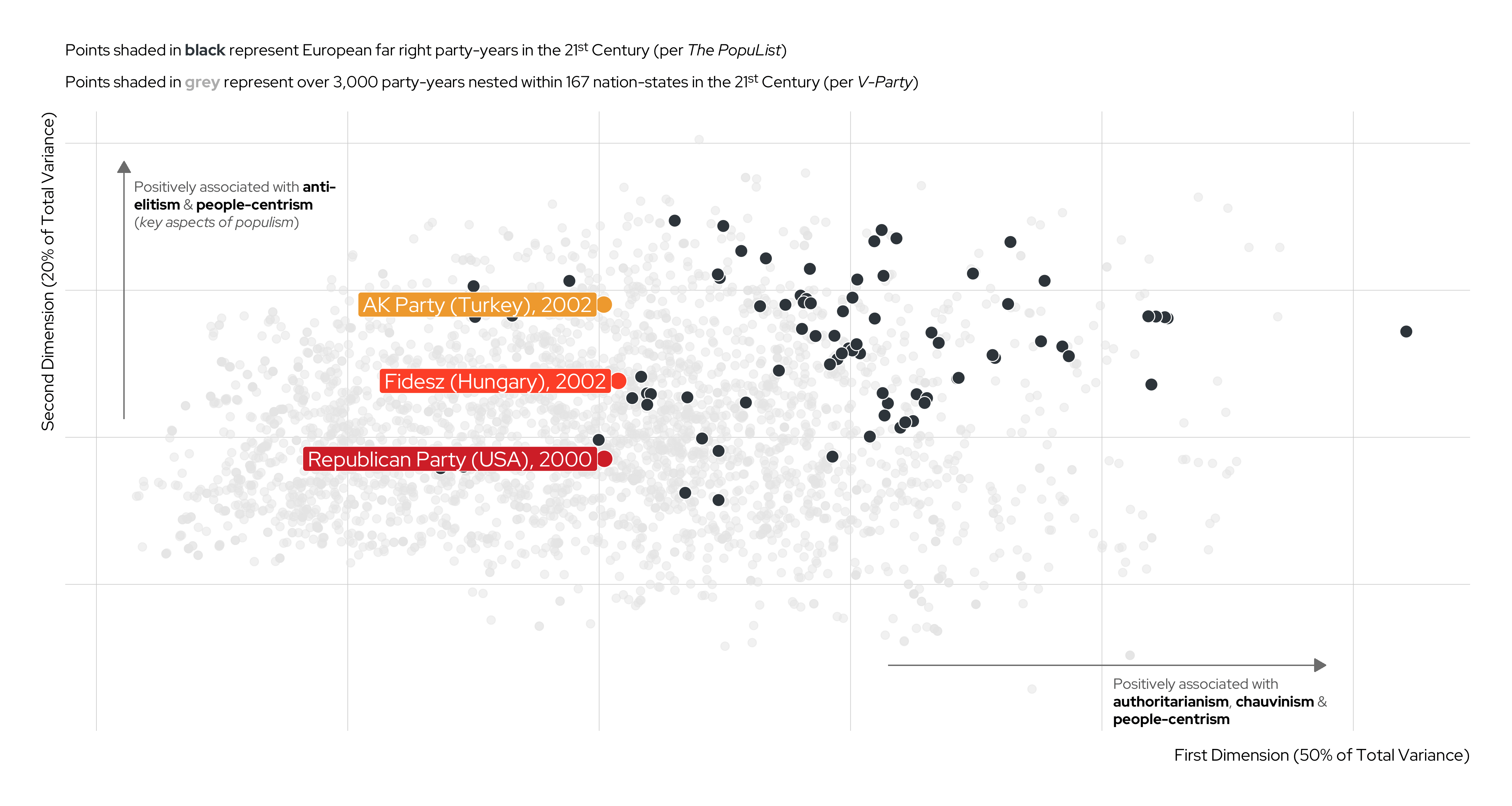
Karim and Lukk’s The Radicalization of Mainstream Parties in the 21st Century
The Two Cultures cont.
| Quantity of Interest | Primary Goals | Key Strengths | Key Limitations |
|---|---|---|---|
| Generative (i.e., Classical Statistics) | |||
| Predictive (i.e., Machine Learning) | |||


Note: To be sure, the putative strengths and weaknesses of these modelling “cultures” have been hotly debated.
Bias-Variance Tradeoff
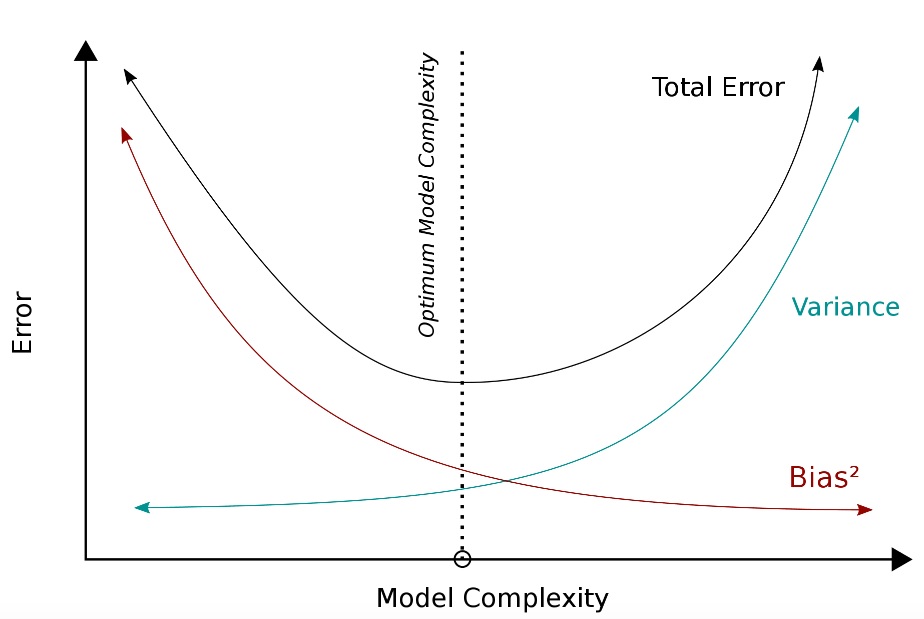
Image can be retrieved here.
Bias emerges when we build SML algorithms that fail to sufficiently map the patterns—or pick up the empirical signal–linking X and Y. Think: underfitting.
Variance arises when our algorithms not only pick up the signal linking X and Y, but some of the noise in our data as well. Think: overfitting.
When adopting an SML framework, researchers try to strike the optimal balance between bias and variance.
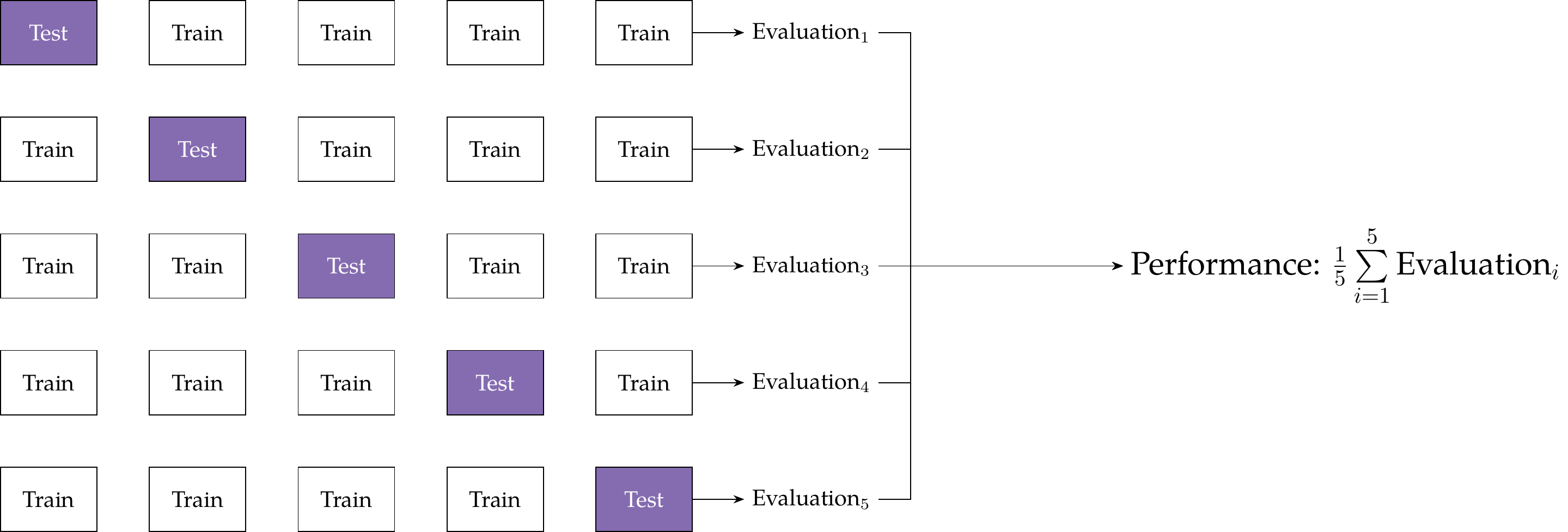
k-Fold Cross-Validation
Unlike conventional approaches to sample partition, k or v-fold cross-validation allows us to learn from all our data.
k-fold cross-validation proceeds as follows:
- We randomly divide our overall sample into k subsets or folds.
- We train our algorithm on k - 1 folds, holding just one group out for model assessment.
- We repeat this process k times—every fold is held out once and used to fit the model k - 1 times.
- We then pool or average the evaluation metrics (e.g., predictive accuracy) for all the held-out runs.
Stratified k-fold cross-validation ensures that the distribution of class labels (or for numeric targets, the mean) is relatively constant across folds.
Stylized example of five-fold cross-validation
References
Note: Scroll to access the entire bibliography

Breiman, Leo. 2001. “Statistical Modeling: The Two Cultures (with Comments and a Rejoinder by the Author).” Statistical Science 16 (3). https://doi.org/10.1214/ss/1009213726.
Donoho, David. 2017. “50 Years of Data Science.” Journal of Computational and Graphical Statistics 26 (4): 745–66. https://doi.org/10.1080/10618600.2017.1384734.
Grimmer, Justin, Margaret E. Roberts, and Brandon M. Stewart. 2021. “Machine Learning for Social Science: An Agnostic Approach.” Annual Review of Political Science 24 (1): 395–419. https://doi.org/10.1146/annurev-polisci-053119-015921.
Llaudet, Elena, and Kōsuke Imai. 2023. Data Analysis for Social Science: A Friendly and Practical Introduction. Princeton, NJ: Princeton University press.
Lundberg, Ian, Jennie E. Brand, and Nanum Jeon. 2022. “Researcher Reasoning Meets Computational Capacity: Machine Learning for Social Science.” Social Science Research 108 (November): 102807. https://doi.org/10.1016/j.ssresearch.2022.102807.
Molina, Mario, and Filiz Garip. 2019. “Machine Learning for Sociology.” Annual Review of Sociology 45 (Volume 45, 2019): 27–45. https://doi.org/10.1146/annurev-soc-073117-041106.
van Loon, Austin. 2022. “Machine Learning and Deductive Social Science: An Introduction to Predictability Hypotheses.” SocArXiv. https://doi.org/10.31235/osf.io/s7uer.
von Hippel, Paul. 2015. “Linear Vs. Logistic Probability Models: Which Is Better, and When?” Statistical Horizons. https://statisticalhorizons.com/linear-vs-logistic/.